What are global and regional effects
Overview
This tutorial is the best place for understanding what global and regional effects are,
why the are a very good choice for interpreting a machine learning model trained on tabular data,
and how to use effector to compute them.
Glossary
- Feature effect or feature effect plot: A visual representation of how a feature influences the model's output. Refers to both global and regional effects.
- Global effect or global effect plot: A 1D plot \(x_i \rightarrow y\) that shows how a feature \(x_i\) influences the model's output \(y\) across the entire dataset.
- Regional effect or regional effect plot: A 1D plot \(x_i \rightarrow y\) that shows how a feature \(x_i\) influences the model's output \(y\) across a subset of the dataset, defined by a condition on another feature. To fully understand the effect of a feature, you need to inspect all regional effects for the particular feature.
Global effects
Why do we care about global effects?
Because they are super simple.
✅ Suppose that you have trained a neural network (1) to predict hourly bike rentals using historical data.
The dataset includes features like hour, weekday, workingday, temperature, humidity, and, of course, \
the target variable: bike-rentals.
- 📌 You can find the full notebook here.
🚀 The model has an average prediction error of about \(\pm43\) bikes. This means that the model is quite accurate, as the target variable has an average value of about \(189\) bikes per hour and a standard deviation of about \(181\) bikes per hour.
📊 After training, you want to understand how the model makes predictions. Feature effect plots provide a visual way to see how each feature influences the model's output.
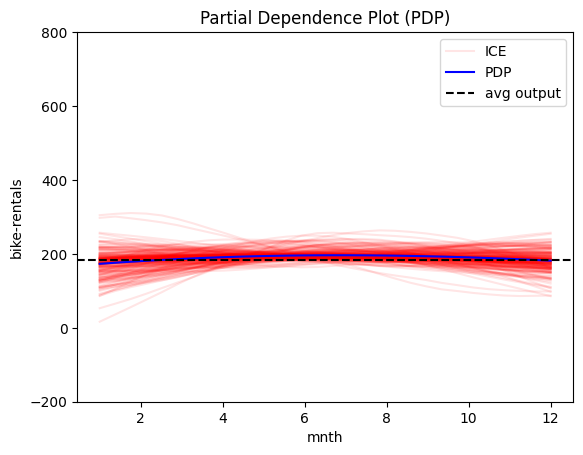
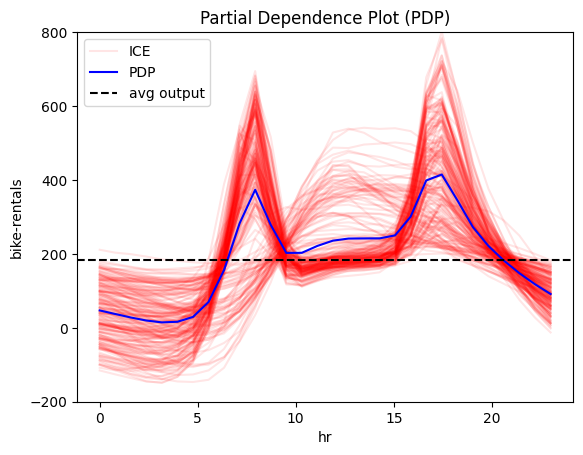
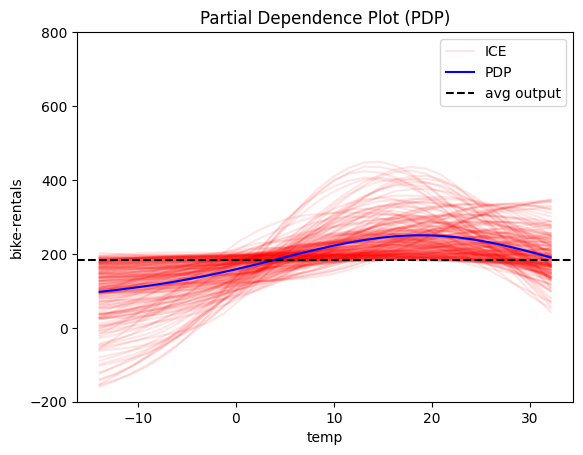
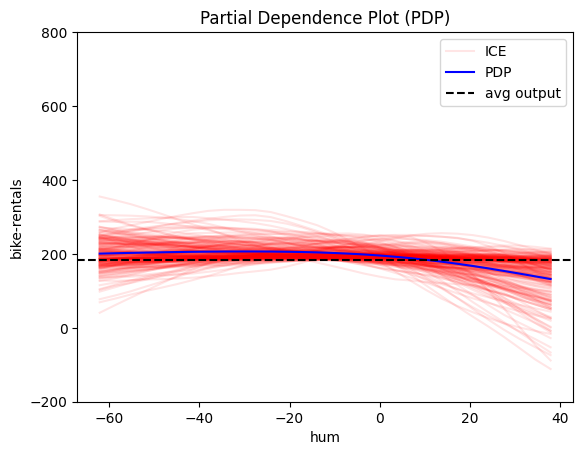
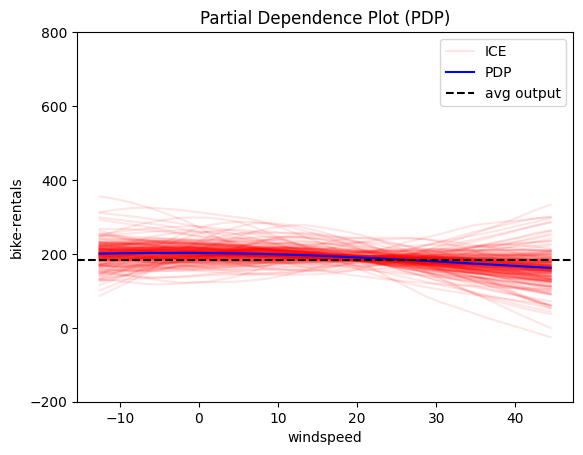
Interesting! The model has "learned" that:
- 🔍 month, humidity, and windspeed have little impact on bike rentals.
- 🌡️ Temperature has a stronger positive effect on bike rentals, with a peak at around 20°C.
- ⏰ hour is the most important feature; let's focus on that!
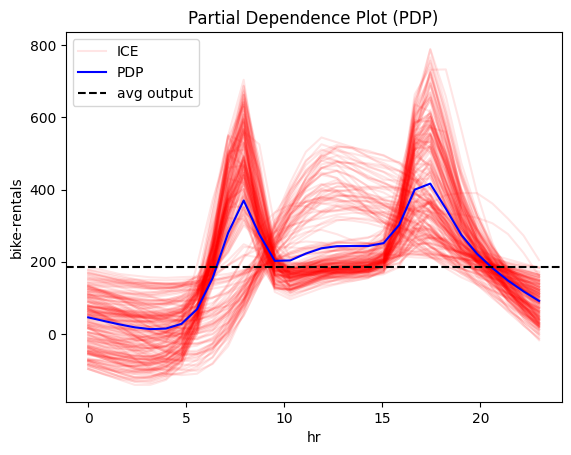
Let's focus on feature hour. We will compute the global effect of the hour feature using three different methods provided by effector:
effector.PDP(X, model).plot(feature=3)
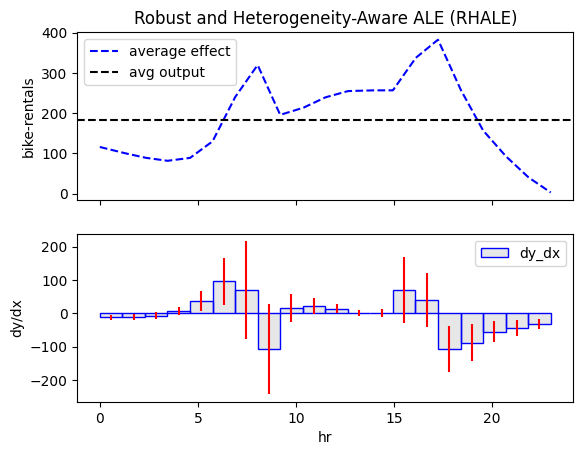
effector.RHALE(X, model, model_jac).plot(feature=3)
effector.ShapDP(X, model).plot(feature=3)
All methods agree on the general trend: there is an abrupt increase in the number of bike rentals at about 8:00 AM (beginning of the workday) and at about 5:00 PM (end of the workday). The following table provides a more detailed interpretation of the plot:
Interpretation: Move along the axis and interpret
| Interval | Description |
|---|---|
| 0-6 | Bike rentals are almost constant and much lower than the average, which is \(\approx 189\) |
| 6-8.30 | Rapid increase; at about 7.00 we are at the average rentals and then even more. |
| 8.30-9.30 | Sudden drop; rentals move back to the average. |
| 9.30-15 | Small increase. |
| 15.00-17.00 | High increase; at 17.00 bike rentals reach the maximum. |
| 17.00-24.00 | A constant drop; at 19.00 rentals reach the average and keep decreasing. |
Global feature effect plots provide an immediate interpretation of the model's inner workings.
Criticism 1: Does it make sense?
It seems reasonable. On a typical workday, people commute between 6:00–8:30 AM and return between 3:00–5:00 PM. But a city transportation expert might have a better perspective.
Criticism 2: Is the explanation valid in all cases?
An expert might point out that this pattern makes sense only on working days. On weekends and holidays, an early peak at about 7:30 AM wouldn't be as logical.
Heterogeneity
Criticism 2 questions whether the explanation applies to the entire dataset. A simple way to check this is to look at the heterogeneity of the global effect:
- 🔴 red ICE curves in PDP
- 🔴 red bars in RHALE plots
- 🔴 red SHAP values in SHAP-DP plots
Let's take a look again:
}
They all indicate a high heterogeneity; there are cases that deviate from the average pattern. Moreover, PDP-ICE analysis highlights two distinct patterns:
- There is one cluster, that follows the global pattern.
- There is a second cluster that behaves differently, with a rise starting at 9:00 AM, a peak at 12:00 AM and a decline at 6:00 PM.
Don't rush to conclusions
What do these two patterns mean?
One could guess that the first pattern is related to the working days, and the second pattern is related to the weekends and holidays.
But this is just a guess. We need to confirm it with the data.
If there is a condition that can be used to separate the two patterns, the regional effect analysis will find it.
Hopefully, there is the workingday feature, so if our guess is correct, we will see two distinct patterns for the hour feature, depending on the value of the workingday feature.
Regional effects
Why do we care about regional effects?
Because they are super simple and provide richer information that global effects.
The global effect is sometimes a weak explanation
When global effect has a high heterogeneity, it is useful to analyze the regional effect. When many instances behave differently from the average pattern, it means that the global effect may hide some important information behind average values. In these cases, regional effect analysis can provide a more detailed explanation.
Regional effects build a partition tree per feature
Regional effects build a partition tree for each feature. In each node of the partition tree, the instances are separated based on a condition on another feature. In each node, the instances are clustered into subregions where the instances behave similarly.
When regional effect can provide a good solution
Unfortunatelly, it does not mean we will always find regional effects that provide a better explanation. That depends on whether conditioning on a feature can separate the instances into subregions where the instances behave similarly. If such a feature exists, regional effect analysis will provide a better explanation. If not, the regional effect analysis will not manage to do something better than the global effect analysis.
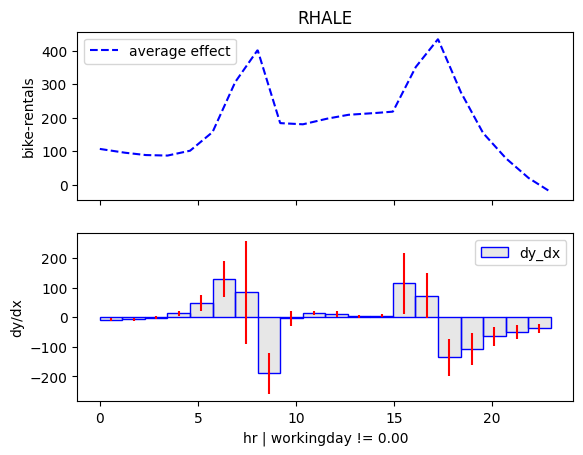
So let's apply regional effect analysis to the \(\mathtt{hour}\) feature.
To print the partition tree, we will use .summary() method of the regional effect analysis classes.
r_pdp = effector.RegionalPDP(X, model)
r_pdp.summary(feature=3)
Feature 3 - Full partition tree:
🌳 Full Tree Structure:
───────────────────────
hr 🔹 [id: 0 | heter: 0.24 | inst: 5000 | w: 1.00]
workingday = 0.00 🔹 [id: 1 | heter: 0.13 | inst: 1548 | w: 0.31]
temp ≤ 4.50 🔹 [id: 2 | heter: 0.06 | inst: 618 | w: 0.12]
temp > 4.50 🔹 [id: 3 | heter: 0.10 | inst: 930 | w: 0.19]
workingday ≠ 0.00 🔹 [id: 4 | heter: 0.12 | inst: 3452 | w: 0.69]
yr = 0.00 🔹 [id: 5 | heter: 0.06 | inst: 1719 | w: 0.34]
yr ≠ 0.00 🔹 [id: 6 | heter: 0.11 | inst: 1733 | w: 0.35]
r_rhale = effector.RegionalRHALE(X, model, model_jac)
r_rhale.summary(feature=3)
Feature 3 - Full partition tree:
🌳 Full Tree Structure:
───────────────────────
hr 🔹 [id: 0 | heter: 5.68 | inst: 13903 | w: 1.00]
workingday = 0.00 🔹 [id: 1 | heter: 0.75 | inst: 4385 | w: 0.32]
temp ≤ 6.81 🔹 [id: 2 | heter: 0.44 | inst: 2187 | w: 0.16]
temp > 6.81 🔹 [id: 3 | heter: 0.60 | inst: 2198 | w: 0.16]
workingday ≠ 0.00 🔹 [id: 4 | heter: 5.44 | inst: 9518 | w: 0.68]
r_shap = effector.RegionalShapDP(X, model)
r_shap.summary(feature=3)
``` Feature 3 - Full partition tree: 🌳 Full Tree Structure: ─────────────────────── hr 🔹 [id: 0 | heter: 0.06 | inst: 500 | w: 1.00] workingday = 0.00 🔹 [id: 1 | heter: 0.02 | inst: 148 | w: 0.30] temp ≤ 4.50 🔹 [id: 2 | heter: 0.01 | inst: 50 | w: 0.10] temp > 4.50 🔹 [id: 3 | heter: 0.02 | inst: 98 | w: 0.20] workingday ≠ 0.00 🔹 [id: 4 | heter: 0.03 | inst: 352 | w: 0.70] temp ≤ 6.81 🔹 [id: 5 | heter: 0.02 | inst: 145 | w: 0.29] temp > 6.81 🔹 [id: 6 | heter: 0.02 | inst: 207 | w: 0.41]
```
That' is quite interesting
All methods confirm our intuition: there are two meaninful subregions based on the workingday feature.
This is the first split in the partition tree and the most important one, for all methods.
Beyond that, methods differ in the next splits.
Let's focus on the first-level splits first.
Depth = 1
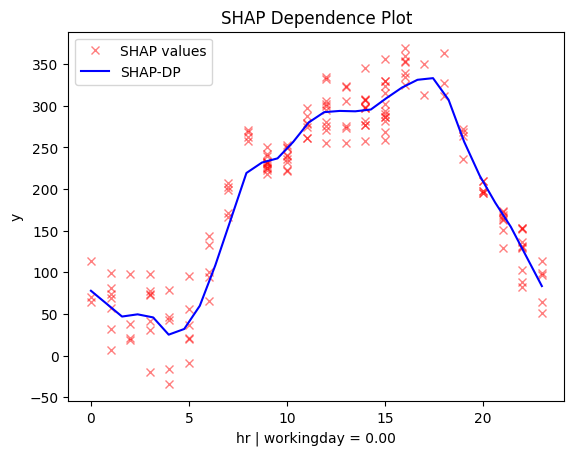
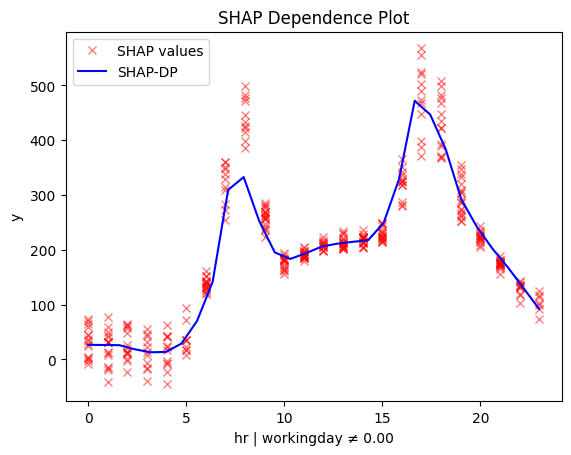
| non-working day | workingday |
|---|---|
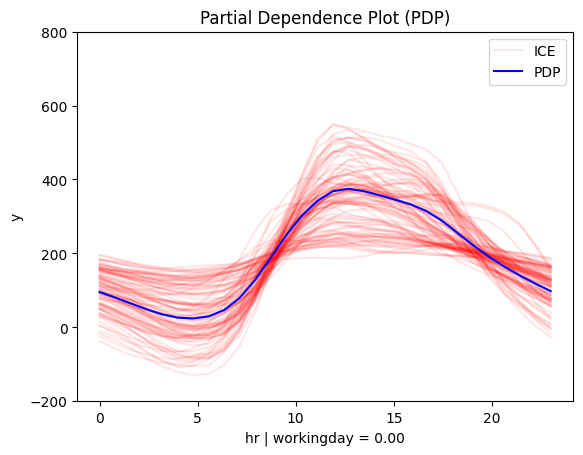 |
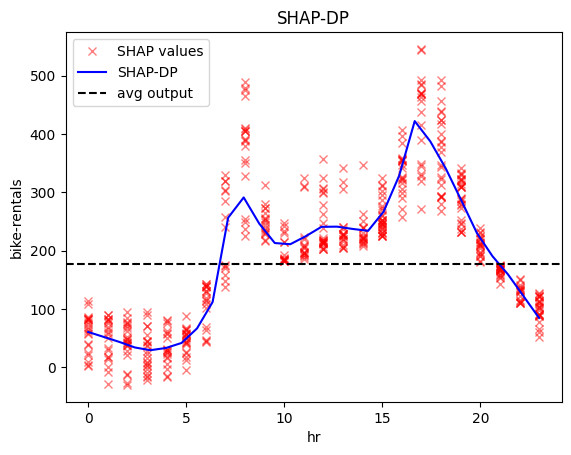 |
| non-working day | workingday |
|---|---|
 |
 |
| non-working day | workingday |
|---|---|
 |
 |
Let's reach some conclusions"
The regional effect analysis confirms our intuition: the data shows two distinct patterns.
📅 Workdays: Rentals rise at 8:30 AM and 5:00 PM, matching commute times.
🌴 Weekends & Holidays: Rentals increase at 9:00 AM, peak at 12:00 PM, and decline around 4:00 PM—a typical leisure pattern.
✔️ This makes sense—temperature matters for sightseeing, but not for commuting.
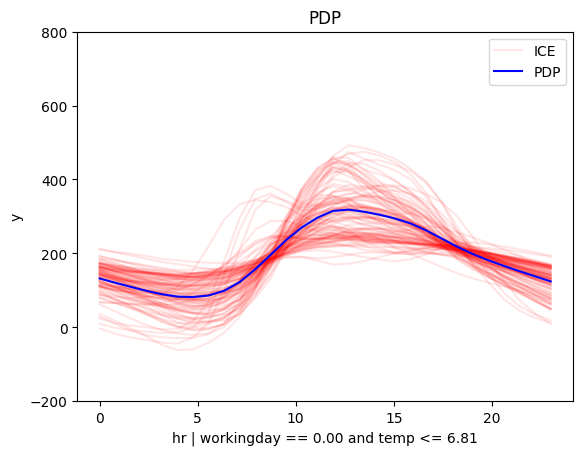
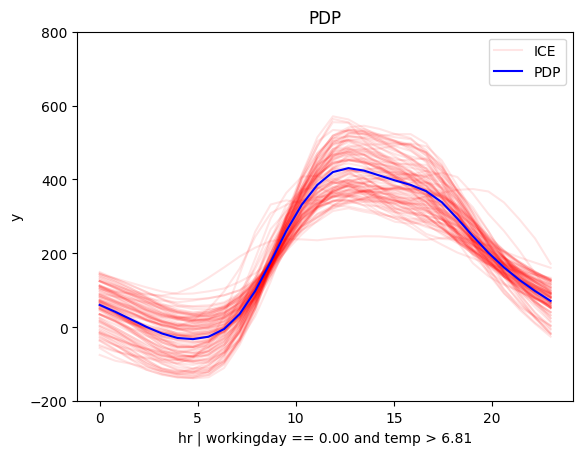
Depth = 2
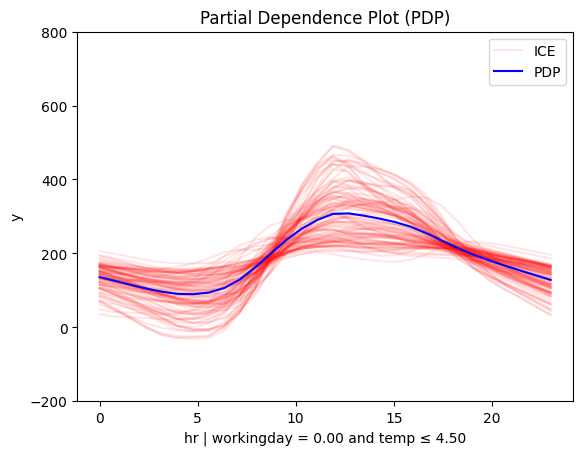
| non-working day and cold | non-workingday and hot |
|---|---|
 |
 |
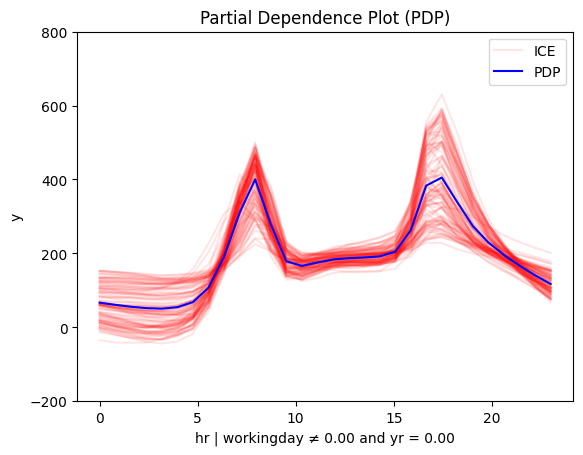
| working day and cold | workingday and hot |
 |
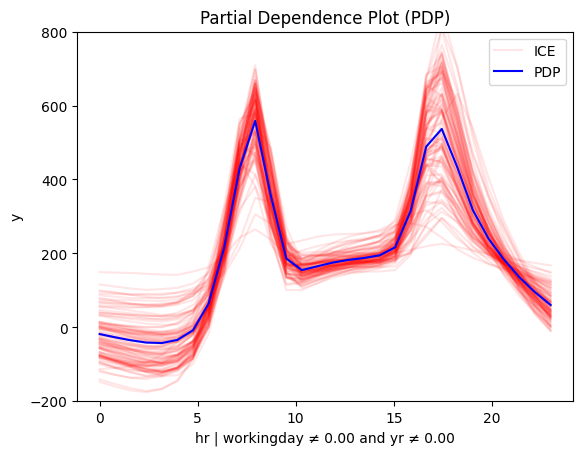 |
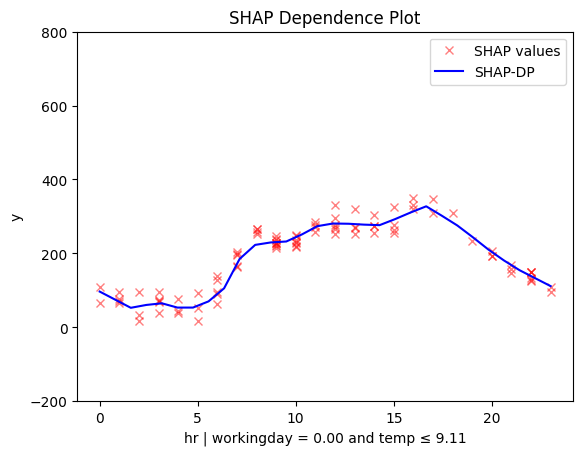
| non-working day and cold | non-workingday and hot | working day |
|---|---|---|
 |
 |
|
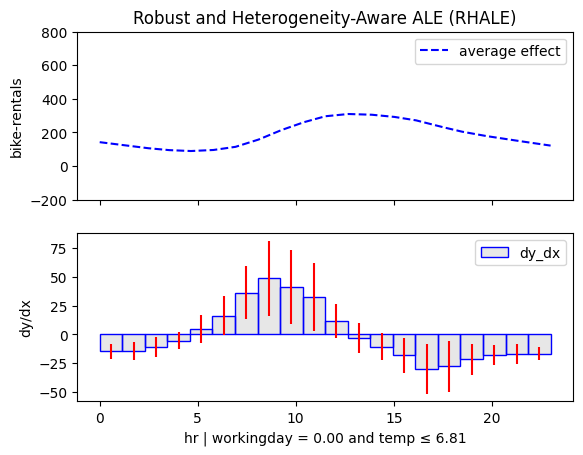
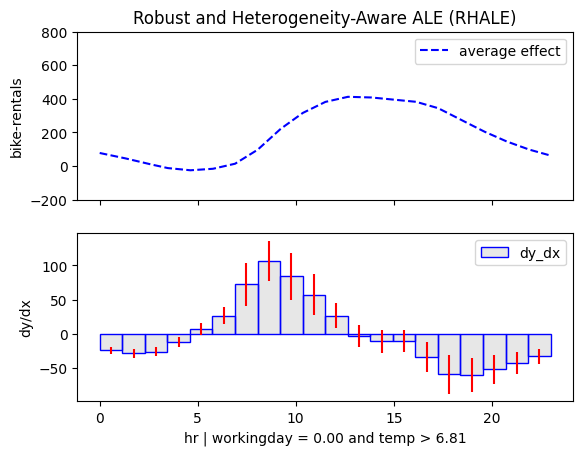
| non-working day and cold | non-workingday and hot |
|---|---|
 |
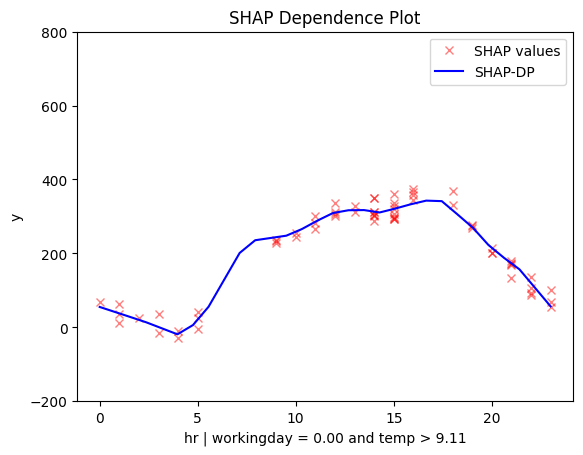 |
| working day and first year | workingday and second year |
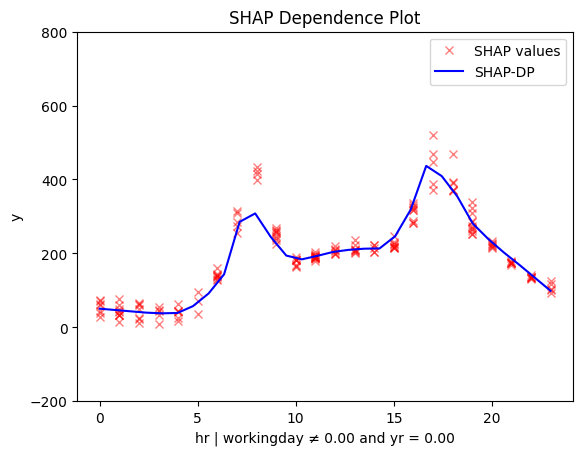 |
 |
Let's reach some conclusions"
The regional effect analysis confirms our intuition: the data shows two distinct patterns.
📅 Workdays: Rentals rise at 8:30 AM and 5:00 PM, matching commute times.
🌴 Weekends & Holidays: Rentals increase at 9:00 AM, peak at 12:00 PM, and decline around 4:00 PM—a typical leisure pattern.
📊 PDP and SHAP-DP go further
They reveal another key factor: temperature. The impact of hour on bike rentals differs on non-working days depending on whether it’s hot or cold.
✔️ This makes sense—temperature matters for sightseeing, but not for commuting.